Freelist
Source Files
└───liblfds710
├───inc
│ └───liblfds710
│ lfds710_freelist.h
└───src
└───lfds710_freelist
lfds710_freelist_cleanup.c
lfds710_freelist_init.c
lfds710_freelist_internal.h
lfds710_freelist_pop.c
lfds710_freelist_push.c
lfds710_freelist_query.c
Defines
#define LFDS710_FREELIST_ELIMINATION_ARRAY_ELEMENT_SIZE_IN_FREELIST_ELEMENTS
Enums
enum lfds710_freelist_query;
Opaque Structures
struct lfds710_freelist_element; struct lfds710_freelist_state;
Macros
#define LFDS710_FREELIST_GET_KEY_FROM_ELEMENT( freelist_element ) #define LFDS710_FREELIST_SET_KEY_IN_ELEMENT( freelist_element, new_key ) #define LFDS710_FREELIST_GET_VALUE_FROM_ELEMENT( freelist_element ) #define LFDS710_FREELIST_SET_VALUE_IN_ELEMENT( freelist_element, new_value ) #define LFDS710_FREELIST_GET_USER_STATE_FROM_STATE( freelist_state )
Prototypes
void lfds710_freelist_init_valid_on_current_logical_core( struct lfds710_freelist_state *fs, struct lfds710_freelist_element * volatile (*elimination_array)[LFDS710_FREELIST_ELIMINATION_ARRAY_ELEMENT_SIZE_IN_FREELIST_ELEMENTS], lfds710_pal_uint_t elimination_array_size_in_elements, void *user_state ); void lfds710_freelist_cleanup( struct lfds710_freelist_state *fs, void (*element_cleanup_callback)(struct lfds710_freelist_state *fs, struct lfds710_freelist_element *fe) ); void lfds710_freelist_push( struct lfds710_freelist_state *fs, struct lfds710_freelist_element *fe, struct lfds710_prng_st_state *psts ); int lfds710_freelist_pop( struct lfds710_freelist_state *fs, struct lfds710_freelist_element **fe, struct lfds710_prng_st_state *psts ); void lfds710_freelist_query( struct lfds710_freelist_state *fs, enum lfds710_freelist_query query_type, void *query_input, void *query_output );
Overview
This data structure implements a freelist.
The implementation performs no allocations. The user is responsible for all allocations (and deallocations), where these allocations are passed into the API functions, which then use them. As such, allocations can be on the stack, on the heap, or as can sometimes be the the case in embedded systems, allocated with fixed addresses at compile time from a fixed global store. Allocations can also be shared memory, but in this case, the virtual addresses used must be the same in all processes.
General usage is that the user calls lfds710_freelist_init_valid_on_current_logical_core to initialize a struct lfds710_freelist_state, and then calls lfds710_freelist_push and lfds710_freelist_pop to push and pop struct lfds710_freelist_elements. A freelist element provides the ability to store a key and a value, both of which are of type void *. The key is not used in any way by the freelist (and of course the value is neither), rather, it is available as a convenience for the user, for situations where data is being transferred between different types of data structures, where some of these data structures do support a meaningful key. The key and value are get and set by macros, such as LFDS710_FREELIST_SET_VALUE_IN_ELEMENT. The SET macros can only be used when an element is outside of the freelist. (Things may seem to work even if they are used on elements which are in the freelist, but it's pure chance. Don't do it).
(See the section below, on lock-free specific behaviour, for an explanation of the unusual init function name.)
The state and element structures are both public, present in the lfds710_freelist.h header file, so that users can embed them in their own structures (and where necessary pass them to sizeof). Expected use is that user structures which are to enter freelists contain within themselves a struct lfds710_freelist_element, and this is used when calling lfds710_freelist_push, and the value set in the freelist element is a pointer to the user structure entering the freelist. This approach permits zero run-time allocation of store and also ensures the freelist element is normally in the same memory page as the user data it refers to.
Lock-free Specific Behaviour
The state initialization function, lfds710_freelist_init_valid_on_current_logical_core, as the same suggests, initializes the state structure but that initialization is only valid on the current logical core. For the initialization to be valid on other logical cores (i.e. other threads where they are running on other logical cores) those other threads need to call the long-windedly named macro LFDS710_MISC_MAKE_VALID_ON_CURRENT_LOGICAL_CORE_INITS_COMPLETED_BEFORE_NOW_ON_ANY_OTHER_LOGICAL_CORE, which will do that which its name suggests.
The freelist internally implements autotuning exponential backoff, which (as can be seen in the benchmark section) improves performance by about a factor of five on a Core i5.
The SET macros (for setting key and value, in stack elements) can only be correctly used on elements which are outside of a freelist, and the GET macros, if called by a thread on a logical core other than the logical core of the thread which called the SET macros, can only be correctly used on a freelist element which has been pushed to the freelist and then popped.
By correctly is it meant to say that the GET macros will actually read the data written by the SET macros, and not some other data.
The freelist should be regarded as a safe communication channel between threads. Any freelist element which has a key and/or value set, and then is pushed to a freelist, will allow any thread which pops that element to correctly read the key and/or value (and by this is it meant to say not just the void pointer of the key and value, but also whatever they point to). This is the only guarantee. Any reads or writes of key and/or value, or what they point to, which occur outside of this pushing and popping pair are not guaranteed to be correct; the data written may never be seen by other threads.
Once a freelist element structure has been pushed to the stack, it cannot be deallocated (free, or stack allocation lifetimes ending due to say a thread ending, etc) until lfds710_freelist_cleanup has returned. Typical usage of course with a freelist is as a store for unused elements, so this restriction in fact is in line with normal usage.
Elimination Array
The freelist also provides support for what is known as an elimination array. This is a method which improves performance. The key performance bottleneck for the freelist is that all threads are trying to read and write to the freelist head pointer. The contention on this one pointer is as high as it possibly can be. A way around this, the elimination array, comes from the insight that a push and a pop operation cancel each other out - so if we have two threads, and one wants to push and the other to pop, if they could somehow communicate, they could solve each others problem without having to touch the freelist head pointer. The pushing thread would hand its element over to the poppping thread - et voilà!
The implemention consists of an array of cache-line length elements, where each of these cache-line length elements is treated as an array of pointers to freelist elements. The pointers are initially set to NULL. When a thread wishes to push, it randomly selects a line and then scans it from left to right. If it finds a NULL pointer, it performs an atomic exchange with the pointer it holds which it wishes to push. If the exchange returns NULL, then the thread has successfully placed its element in the elimination array and its push operation is complete. If the exchange returns a pointer, then another thread managed to grab that slot before the current thread; as such, the current thread's element is now in the elimination array, but it now holds another pointer, which it still has to deal with - so it continues to scan the selected cache line for another NULL pointer. If no NULL pointers are found, the thread pushes as normal to the freelist, using the freelist head pointer.
When a thread wishes to pop, it randomly selects a cache line in the elimination array and as with pushing then scans it from left to right. A popping thread howeer is not looking for NULLs, but for pointers to freelist elements, as set by the pushing threads. If a pointer is found, the thread performs an exchange with NULL. If the exchange returns a pointer, then the thread has successfully obtained an element from the elimination array and the pop operation is complete. If the exchange is NULL, another thread managed to grab that element just before the current thread. The slot in the elimination layer is still set to NULL, and so still is correctly available to pushing threads, and the popping thread continues to scan the cache line. If no pointers are found, the thread pops as normal from the freelist, using the freelist head pointer.
This implemention leads to two considerations.
Firstly, thread need to randomly select cache lines in the elimination array. This implies random number generation. Where liblfds targets a bare C implementation, and where the C implementation of rand() is anyway typically a function call, slow internally, of exceedingly poor quality and not thread safe, liblfds has implemented its own PRNG API. This API offers both a lock-free and a single-threaded PRNG. The lock-free PRNG has internally a single word-length store which is the target of an atomic add per random number generation. This means the more threads use a single lock-free PRNG instance, the more contention there is, and the worse performance becomes. If the freelist were to use a lock-free PRNG for random number generation, the performance hit taken thereby would massively and profoundly outweight the performance gain from the elimination array. As such, the freelist uses a single-threaded PRNG, and so being single-threaded is provided by the user to the lfds710_freelist_push and lfds710_freelist_push functions.
Providing a per-thread state can be onerous or even impossible and as such, the PRNG argument to the push and pop functions can be NULL even though the elimination array is in use (the elimination array is optional; the user can indicate it is not to be used). In this case, in the push function, the actual value of the freelist element pointer argument is passed through the PRNG mixing function and used as the random value to select a cache line, and in the pop function, the actual value of the freelist element pointer to poiner argument is likewise used. As such, if a given thread has for example a single freelist pointer on its stack and is always using that pointer to pop and then push elements, that thread will always be choosing the same cache line from the elimination array, and the performance gain from the elimination array will be reduced.
Secondly, where a popping thread only scans a single line of the elimination array before turning to the freelist, if the freelist proper is empty and the popping thread scans an elimination array line which is empty, the popping thread will fail to pop - even though there could be available freelist elements in other elimination array cache lines. The solution to this is to provide additional elements when initializing the freelist array, equal to the size of the elimination array minus one cache line, so that the expected number of elements will always be available. The number of additional elements required can be obtained from a call to lfds710_freelist_query.
The size of the elimination array is chosen by the user. If the elimination array is very large, the overhead of additional elements is large. If the elimination layer is very small, the benefits are reduced. The recommended size is to consider the typical number of threads generally using the freelist, and have one cache line per thread.
Note that use of the array is optional - a NULL pointer and 0 size can be passed in (and then the psts arguments to the push and pop functions are ignored. The main purpose for this option however is to facilitate the liblfds test suite, as the elimination array by randomizing the order of elements moving into and out of the freelist prevents certain forms of testing.
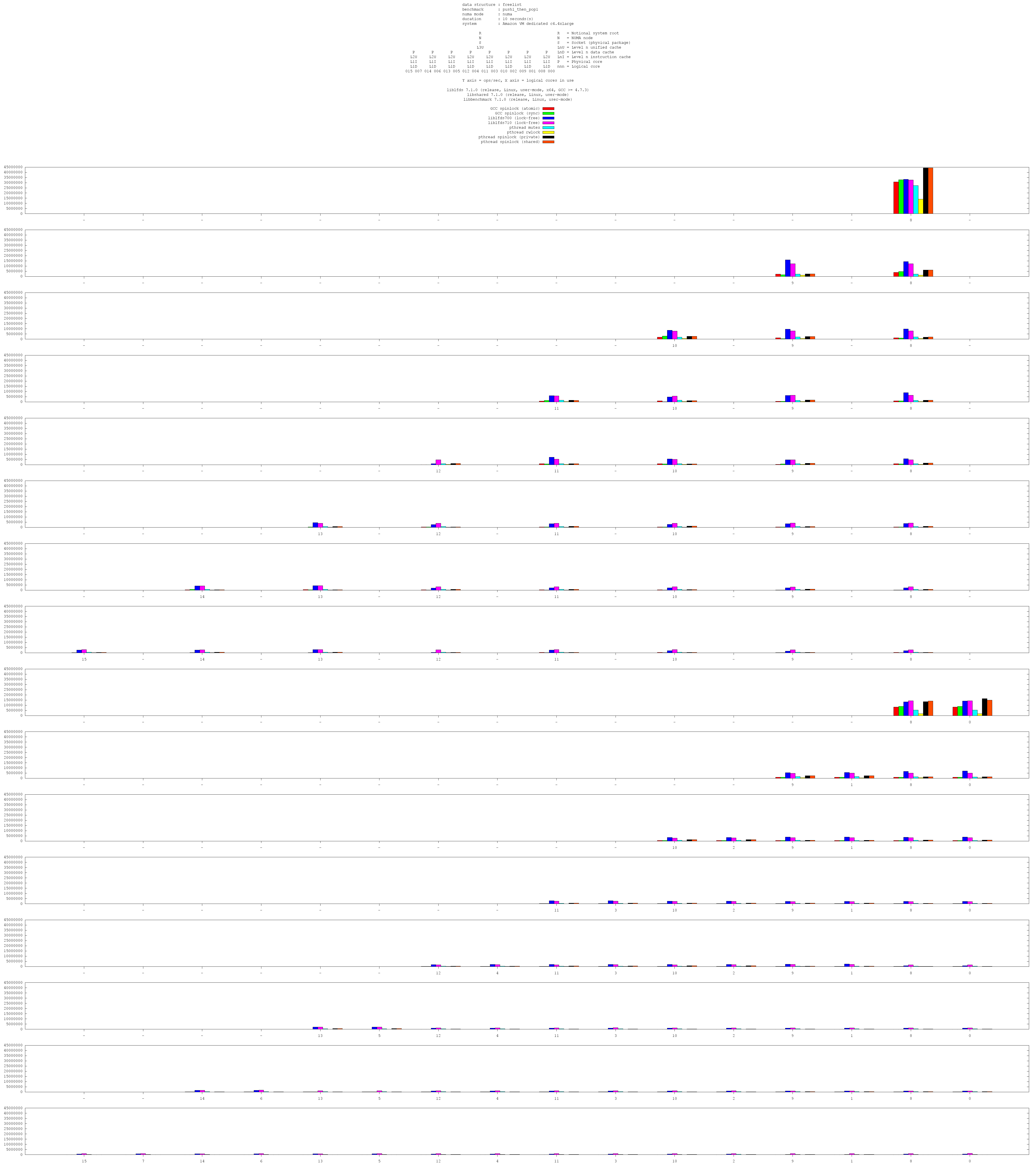
Benchmark Results and Analysis
| freelist | ||
|---|---|---|
| ARM32 | x64 | |
| Raspberry Pi 2 Model B | AWS dedicated VM | Core i5 |
.1200x1800.png) |
 |
.1200x1800.png) |
A benchmark operation is a pop-push pair.
A freelist, in its straightforward form, has a single memory address which experiences intense memory contention - the head pointer in the freelist state. This means that such implementations cannot scale. As the core count rises, the single-threaded performance is simply distributed amongst the cores, with increasing inefficiency losses from contention.
The lock-free implemention in 7.0.0 features exponential backoff, which improve performance by a factor of about 5x. (Benchmarks for earlier versions are not yet available - however, during development, benchmarks were made with and without backoff). With contended memory locations, backoff is absolutely profoundly fundamentally important. Without it, performance is no greater than locking solutions.
Release 7.1.0 features autotuning exponential backoff, which is absolutely necessary, as the optimal backoff value varies by many factors, such as the processor/memory topology and how busy the freelist is at the current time (how mnay threads are attempting concurrent accesses), such that the optimal value is never fixed and so cannot be set statically.
However, release 7.1.0 also implemented an elimination layer. This acts to address the memory contention on the freelist head pointer - it distributes access over a number of cache lines (the user can choose how many, but if we consider the maximum number of threads which could concurrently access the freelist, it should be at least one cache line per thread).
This has NOT led to the expected massive performance gains, indeed it has led in many cases to perforannce loss, and it is not yet apparent why. One possible reason is the lack of backoff in the elimination layer. Real gains are shown on the 16 core AWS VM, when one thread is run per physical processor. With six or more threads running, the elimination layer roughly doubles performance. However, this is still entirely out of line with expectations. The expectation is single-thread like performance which scales.
For now, it's adviseable not to use the elimination layer (it is optional), but to use 7.1.0 rather than 7.0.0 (to get the autotuning backoff).
Changing subject, one particular note of interest is that of the performance of the new GCC "atomic" intrinsics vs the old GCC "sync" intrinsics. The underlying atomic operation is identical, but the old sync instrincs always issue a memory barrier, where the new atomic instrincs only issue a memory barrier if you tell them to.
If we look at the ARM32 gnuplot, at the single core chart, at the first two bars, we see the first bar (GCC atonic) is about 25% higher than the second bar (GCC sync). The freelist pop operation does not require a memory barrier, and so the difference between those two benchmarks is and is only the extra memory barrier being issued by the old sync atomic during the pop operation.
White Paper
This is an implementation of the classic lock-free data structure, by R. K. Treiber, back from 1986. Treiber published a long pamphlet, "Systems Programming: Coping with Parallelism", which amongst other things described the use of compare-and-swap on some contemporary IBM mainframe hardware to implement a stack (conceptually identical to a freelist).
License
Unclear. However, no patent is known and the design is massively used throughout the industry. The autotuning backoff is derived from the design of ethernet backoff (it is ethernet backoff, but without the random component) but the implementation is native to liblfds. The elimination layer was inspired by a sentence (the insight that a push and pop cancel each other out) from a paragraph from the introduction in the white paper Hendler, Shavit, Yerushalmi - A Scalable Lock-Free Stack Algorithm, but the white paper was not read and so its implementation is unknown, and so the implementation used here is native to liblfds.
Example
#include <stdio.h>
#include <stdlib.h>
#include "liblfds710.h"
struct test_data
{
struct lfds710_freelist_element
fe;
int
buffer[1024];
};
int main()
{
lfds710_pal_uint_t
additional_element_count,
total_element_count;
struct lfds710_freelist_element
* volatile (*elimination_array)[LFDS710_FREELIST_ELIMINATION_ARRAY_ELEMENT_SIZE_IN_FREELIST_ELEMENTS];
struct lfds710_freelist_element
*fe;
struct lfds710_freelist_state
fs;
struct lfds710_prng_st_state
*psts;
struct test_data
*td,
*temp_td;
/* TRD : the caller decides the elimination array size
must be multiples of sizeof(struct lfds710_freelist_element) * LFDS710_FREELIST_ELIMINATION_ARRAY_ELEMENT_SIZE_IN_FREELIST_ELEMENTS
and aligned on LFDS710_PAL_ATOMIC_ISOLATION_IN_BYTES
*/
elimination_array = aligned_malloc( 4 * sizeof(struct lfds710_freelist_element) * LFDS710_FREELIST_ELIMINATION_ARRAY_ELEMENT_SIZE_IN_FREELIST_ELEMENTS, LFDS710_PAL_ATOMIC_ISOLATION_IN_BYTES );
lfds710_freelist_init_valid_on_current_logical_core( &fs, ea, 4, NULL );
// TRD : the freelist push and pop functions benefit from a PRNG (it's not mandatory, but use it if you can)
lfds710_prng_st_init( &ps, LFDS710_PRNG_SEED );
/* TRD : so now we want a freelist with say 100 elements in
however, we must allocate some additional elements because of the elimination array
*/
lfds710_freelist_query( &fs, LFDS710_FREELIST_QUERY_GET_ELIMINATION_ARRAY_EXTRA_ELEMENTS_IN_FREELIST_ELEMENTS, NULL, (void *) &additional_element_count );
total_element_count = 100 + additional_element_count;
td = malloc( sizeof(struct test_data) * total_element_count );
for( loop = 0 ; loop < total_element_count ; loop++ )
{
LFDS710_FREELIST_SET_VALUE_IN_ELEMENT( td[loop].fe, &td[loop] );
lfds710_freelist_push( &fs, &td[loop].fe, &ps );
}
// TRD : now we have a freelist with a 100 guaranteed elements (the extra in the elimination array might be available)
// TRD : pop the freelist
while( lfds710_freelist_pop(&fs, &fe, &ps) )
{
temp_td = LFDS710_FREELIST_GET_VALUE_FROM_ELEMENT( *fe );
// TRD : here we can use temp_td->buffer
}
lfds710_freelist_cleanup( &fs, NULL );
free( td );
return( EXIT_SUCCESS );
}